Kimi智能助手
软件类型:办公软件软件大小:139.30MB软件平台:WinALL软件语言:简体中文
标签: Kimi智能助手
查看详情
备受瞩目的AI技术提供商月之暗面正式宣布,其
开放平台的核心功能“上下文缓存”(Context Caching)已正式启动公开测试。这项创新技术的发布,意味着AI大模型在处理长文本以及应对频繁请求的场景时,性能与成本效率将实现双重提升。

据官方介绍,上下文缓存技术借助预先存储可能被高频请求的海量数据或信息,大幅缩减了模型的处理时长,减少了运算开支。在维持现有API定价不变的情况下,这项技术可让开发者使用长文本旗舰大模型的成本最多降低90%,同时还能明显加快模型的响应速度,首Token延迟的下降幅度达到了83%之高。
预设内容丰富的QA Bot:如Kimi API小助手,能够快速响应用户提问,提供精准答案。
固定文档集合的频繁查询:如上市公司信息披露问答工具,确保信息快速准确获取。
静态代码库或知识库的周期性分析:各类Copilot Agent能更高效地进行代码审查和知识检索。
瞬时流量巨大的AI应用,例如哄哄模拟器、LLM Riddles等爆款产品,要保证在高并发场景下依旧能够流畅运行。
交互规则复杂的Agent类应用:提升用户体验,减少等待时间。

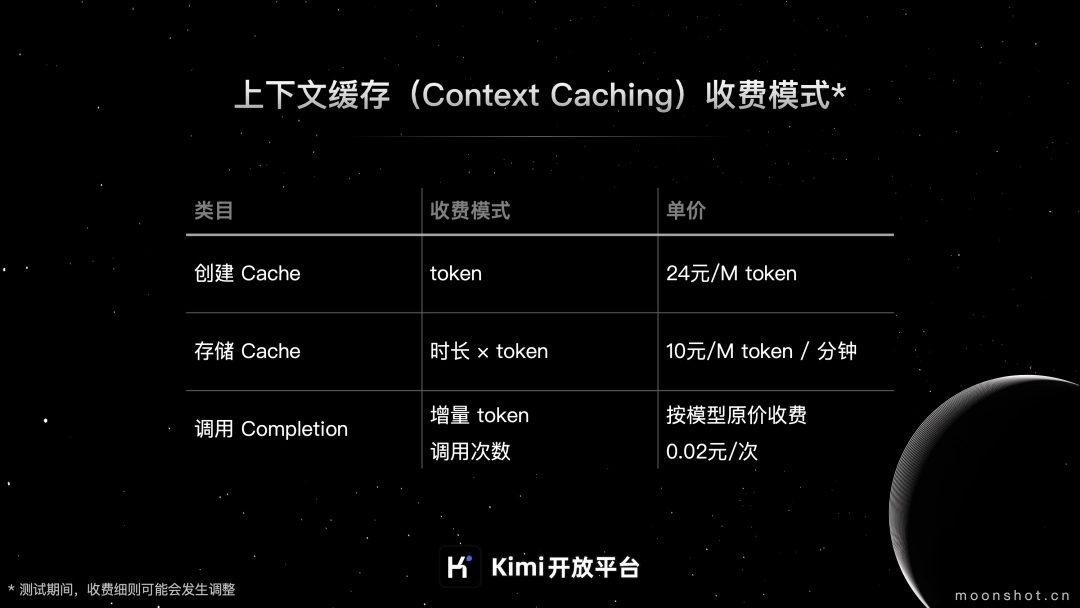
为了平衡技术成本与用户体验,月之暗面为上下文缓存功能设计了详尽的计费模式,主要包括三个部分:
Cache创建费用:成功创建Cache后,按Cache中的Tokens实际量计费,费用为24元/M token。
Cache存储费用:在Cache存活期间,按分钟收取存储费用,费用为10元/M token/分钟。
Cache的调用费用由两部分构成:一是增量token收费,二是调用次数收费。其中,增量token的计费标准与模型原价一致;调用次数方面,在Cache的存活有效期内,当用户通过chat接口发起对已创建Cache的请求且匹配成功时,将按照每次0.02元的标准收取费用。
本次公开测试周期为3个月,自该功能正式上线当天起算。在公测阶段,Context Caching功能将优先向Tier5级别的用户开放,其余用户的具体开放时间会再行告知。另外,公测期间的定价或许会依据用户反馈与市场需求做出调整,以此保障技术能够持续优化,用户体验也能不断得到提升。
月之暗面Kimi开放平台这次推出的上下文缓存功能,无疑为AI大模型在文本处理领域的应用开拓了新的方向。随着公测的持续推进,相信这项技术将引领AI领域的新一轮革新,为开发者提供更高效、更经济的解决方案。